
Tras mirar cómo eran los márgenes de error en encuestas virtuales, quería mirar si se podían estimar los errores de los resultados cocinados. Para ello, era necesario tener algún método sencillo que se pudiera tomar como sucedáneo de la cocina demoscópica, y de paso ver hasta qué punto las suposiciones demoscópicas son razonables o no.
Un método que ha mostrado Jesus Martinez-Garcia es probar con multiplicar por un factor a la intención de voto directa. El sistema no me convence al ser unos factores arbitarios: la única forma sería considerar que el factor es el mismo para todos los partidos y simplemente hacer un ajuste para que la suma de los porcentajes de los votos válidos sea 100, pero no me parece que el electorado se suela comportar así.
Un valor que parece que es fundamental a la hora de cocinar los datos es el recuerdo del voto según indica la metodología del CIS. El recuerdo del voto es usado para corregir los sesgos de las muestras o de la preferencia a contestar a encuestas. Un método muy sencillo de cocina es entonces separar las intenciones de voto por el partido que se ha votado y luego ponderar cada grupo por su peso real en las pasadas elecciones.
Como ejemplo voy a mostrar esta cocina para última encuesta publicada por Metroscopia, realizada a principios de abril. Así, que el método consta de dos pasos. Primero hay que separar la intención de voto a cada partido, como se indica en la siguiente tabla donde las columnas corresponde al partido que se ha votado en las pasadas elecciones generales y en las filas el porcentaje con el que se votaría al partido correspondiente por cada grupo de recuerdo de voto, sin contar a los que no saben a quién van a votar:
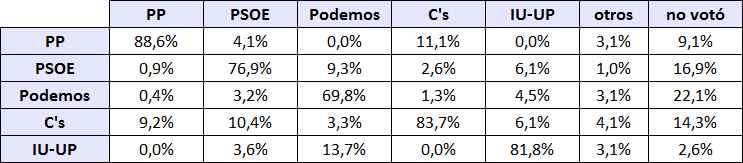
Así, el PP es el partido cuyos votantes dicen que más van a repetir el voto (88,6 %) mientras que los de Podemos son los que menos (69,8 %). Si se usa el porcentaje de votos que tuvo cada partido y se ajusta para que haya un 100% de votos válidos, se obtiene la siguiente tabla que indica el porcentaje de voto válido que iría a cada partido (en filas) desde los votantes de los partidos de las últimas elecciones generales (en columnas):

Para el caso de los que no votaron, en vez de tomar su peso real, tomé su peso relativo, porque creía que sino se daba mucho peso a los que no votaron, que según mi sesgo no suelen volver a votar. Si se suman los porcentajes de cada fila entonces se obtiene la estimación de voto de cada partido.
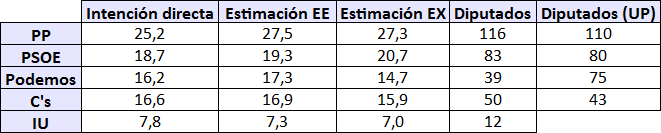
En la siguiente tabla comparo esta estimación (indicada con EX) con la calculada por Metroscopia (M), además de con la calculada directamente solo con la intención directa de voto:

La estimación así calculada no es igual a la calculada por Metroscopia, pero se parece más a ella que la calculada directamente por intención directa de voto. Por ejemplo, supongo que en Metroscopia hayan ponderado por diferentes estratos demográficos (edad, población de residencia, etc.) para compensar los sesgos debidos a que es una encuesta telefónica.
En esta simple estimación ya se observan efectos habituales de las estimaciones de las encuestas: que el voto del PP sube cuando se compara con la intención directa de voto y el de otros partido, notablemente IU, baja.
Las otras columnas indican la estimación de diputados con un método de extrapolación, ya sea considerando que Podemos e IU van juntos o separados (UP, unidad popular).
El método de estimación de voto lo he utilizado también para la última encuesta de El Español de finales de marzo:
Para calcularla, se han utilizado las tablas de cruces que proporcionan. Como había números fraccionarios, entiendo que incluyen la ponderación demográfica de las muestras, más necesario aún en este caso al ser un sondeo basado en un panel de internet.
Y para el sondeo del CIS de enero:

Una de las cosas que me interesaba intentar estimar es el margen de error de las muestras, sabiendo el método de cocina. Así, por medio de simulaciones de votaciones con las intenciones de votos dadas por las encuestas he podido calcular los márgenes de error, para una confianza del 95%:
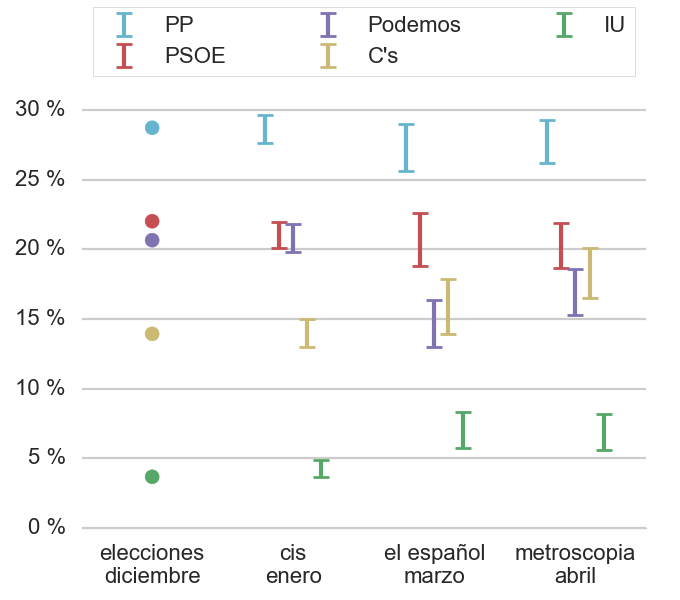
Curiosamente, los márgenes de error son menores que una encuesta virtual perfecta, lo que parece sospechoso. Creo sin embargo que esto es debido a que se usan grupos de recuerdo de voto, cuyo porcentaje de voto ya está determinado sin incertidumbre, lo que hace que no se propaguen errores debidos al usar como denominador el número de votantes válidos. Los errores mostrados son solo los estadísticos, y no se incluye ningún error por la cocina usada, por lo que se puede considerar que es una estimación del margen de error por su parte inferior.
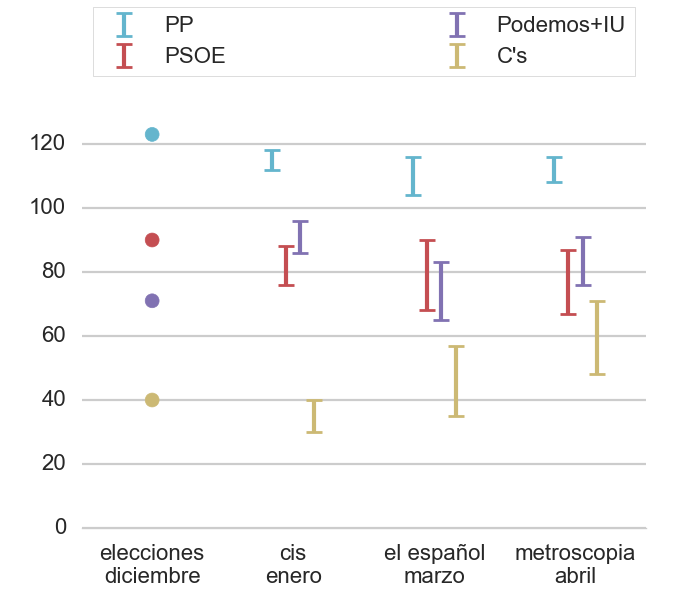
Mirando la gráfica, se observa que más o menos el voto al PP y el PSOE no ha cambiado desde las elecciones o acaso descienden un poquito. El voto de Podemos sí que parecería que ha bajado más, mientras que tanto C’s como IU suben. Esto se ilustra en la primera tabla mostrada porque Podemos tiene el menor porcentaje de votantes que dicen que van a repetir votos, e incluso alrededor del 10 % declaran que van a votar a IU.
En la siguiente gráfica se muestra la evolución de la estimación de escaños con el método de extrapolación. Los márgenes de error se han determinado simplemente calculando la extrapolación con el mínimo y máximo del rango de error de la estimación, sin añadir la incertidumbre asociada al método de extrapolación:
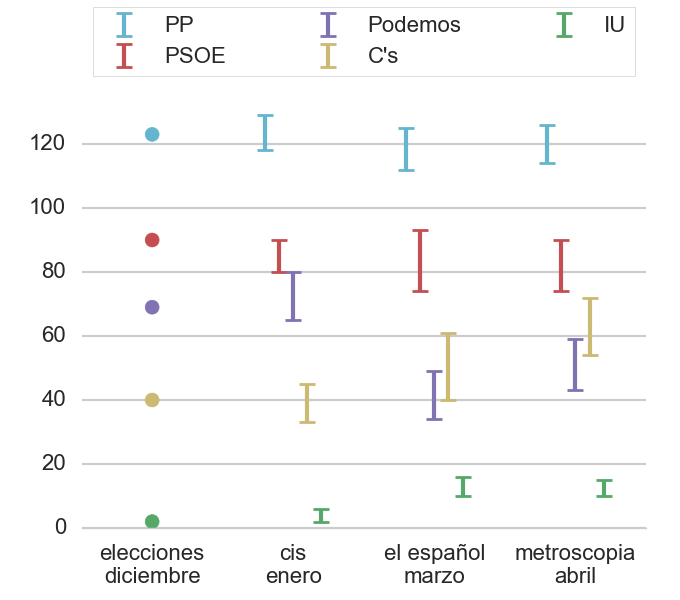
Finalmente se muestra la estimación del número de escaños si se sumaran los votos de Podemos e IU a la hora de calcular los escaños:
La comparación de este gráfico con el anterior indica claramente la conveniencia de la confluencia de Podemos e IU, ya que iban a sumar unos cuantos escaños más (mirando en las tablas de este artículo, entre 14 y 24) si van juntos, siempre que mantengan los mismos votantes que por separado, claro. De esta forma dificultarían mucho una mayoría absoluta de PP y C’s.
Por último, está la pregunta de hasta cuánto nos podemos fiar de las encuestas tras los últimos fracasos, como en las elecciones generales. Diría que la información demoscópica es muy golosa, pero hay que tratarla con sumo cuidado. Sin embargo creo que tras las últimas elecciones el acierto demoscópico debería mejorar bastante, al entender que variables como el recuerdo de voto son más veraces. Sin embargo, lo que no pueden prever las encuestas es la volatibilidad del voto, donde buenas campañas electorales —o pésimas campañas del adversario, que suele ser más frecuente— pueden cambiar mucho el panorama electoral.
Adenda
De la entrevista a Carolina Bescansa:
Desde 2014 hemos asistido a un proceso de disolución de las lealtades electorales partidistas. Antes el 10% o el 15% de la gente elegía su voto en campaña y ahora es el 30% o el 40%. El otro día viendo los datos de una encuesta me llamó mucho la atención que a pesar del agotamiento que detectamos en nuestro alrededor, porque la gente está hasta las narices y aburrida, los datos revelan que el interés por la política sigue muy alto, incluso más que antes del 20D. Ahora hay mucho electoral fluctuante y va a decidir su posición en función de lo que los partidos hagan en estas semanas.
Si la estimación electoral siempre es difícil lo es más cuando lo que sí sabes es que la volatilidad es muy alta. Ahora bien, lo que no explica es que estemos viendo encuestas y análisis que dicen de una semana para otra que el 10% del electorado cambia el sentido de su voto. Eso es un disparate que sabe cualquiera que se dedique a hacer encuestas.
Bon dia,
Jo diria que el record de vot és valuós, però que cal tindre en compte si també s’ha produït un fenomen de «vergonya de vot». Així, el PP sempre tenia menys RV, i per això la cuina els era tan favorable. No es valorava que antics votants n’estaven avergonyits.
Amb mostres amples, la tendència hauria de ser a assemblar-se molt al vot real. Si no, o bé les mostres són esbiaixades i poc vàlides; o bé està funcionant la VV.
Un salut!
eljuliet,
El problema es la gente que dice que no sabe a quién votar o que no quiere contestar, que puede tener su sesgo. Así que hay diferentes métodos para asignarles el voto: uno sería usando el del conjunto de la encuesta y otro hacerlo por segmentos demoscópicos. Al final es el cocinero el que tiene que tirar más por un método o por otro, según sus conocimientos de la situación «a priori».
Tampoco creo que sea fácil hacer una muestra de la población sin sesgos, sobre todo si se hacen por teléfono o por panel de internet, e incluso aunque sean a domicilio como el CIS, ya que no es fácil hacer una selección puramente aleatoria entre toda la población de forma eficiente. En principio, ciertos sesgos se podrían corregir, pero si son conscientes de ellos (territorial, núcleos poblacionales, sexo, edad), pero a costa de desvirtuar la muestras: no se está haciendo una muestra grande, sino submuestras de poblaciones más pequeñas.
Pues nada, ha sido publicar tus pronósticos de sorpasso y a negociar que se han puesto Podemos e IU. Puede ser muy bonito ver como el PSOE se destruye en, ¿cuanto? ¿dos años desde las europeas?
Como comentario, no sé cómo estás subiendo las imágenes, pero igual podías descargar al servidor copiando las tablas en texto (con wordpress no debería costar mucho) porque de tres veces que he entrado, dos las imágenes no se han cargado.
Johnnie,
Tengo la idea de que se maneja mejor el formato de las tablas con una imagen, porque en html hay que interaccionar con los estilos de WordPress, pero tampoco he probado últimamente.
El problema que cuentas no me ha dado a mí, además teniendo en cuenta que las imágenes son muy ligeras, pero a veces el servidor de LPD tiene sus cosas.