
import datetime, requests
url_plantilla = 'http://servicios.ine.es/wstempus/js/ES/DATOS_SERIE/{codigo}?nult={num_datos}'
codigo = "EPA87"
num_datos = 4
url = url_plantilla.format(codigo=codigo, num_datos=num_datos)
respuesta = requests.get(url)
datos = respuesta.json()
print(datos['Nombre'])
for x in datos['Data']:
fecha = datetime.date.fromtimestamp(
x['Fecha'] // 1000)
ocupados = x['Valor']
print(fecha, ocupados)
Obteniendo como resultado:
Total Nacional. Ambos sexos. De 16 y más años. Ocupados. Personas. 2015-10-01 18094.2 2015-07-01 18048.7 2015-04-01 17866.5 2015-01-01 17454.8
tl;dr
El #INE ha publicado API para acceso a datos y metadatos en formato Json. Más info: https://t.co/Aw6Vv8CSng pic.twitter.com/EEhcSkLl9D
— INE España (@es_INE) February 3, 2016
Desde hace unos días, el Instituto Nacional de Estadística (INE) permite acceder a sus datos en formato JSON. El INE es la organización que se encarga de elaborar las estadísticas a nivel nacional, como las encuestas sobre la población activa, la inflación o el producto interior bruto. El JSON es un formato para el intercambio de datos que está implementado en muchos lenguajes de programación, por lo que ahora es mucho más fácil automatizar la recolección de los últimos datos publicados por el INE.
El INE ha publicado un manual de cómo acceder a sus datos con JSON. Lo que aquí se va a mostrar es un simple tutorial, basado en el lenguaje de programación Python 3. Aunque también se podría haber hecho usando módulos estándar de Python, se han empleado algunos módulos que son muy populares y que están incluidos en distribuciones como Anaconda. Este tutorial también podría ser útil para otros lenguajes de programación, ya que el método para acceder a los datos del INE será similar.
Este tutorial se basará en la lectura de una serie temporal del INE. El INE publica los datos en tablas que pueden contener muchas series temporales. Para acceder a una serie del INE en JSON basta con leer la página web que tiene una URL (dirección web) de esta forma:
http://servicios.ine.es/wstempus/js/ES/DATOS_SERIE/{codigo}?nult={num_datos}
Donde {num_datos} debe sustituirse por el número de últimos datos que se quieren leer y {codigo} es el código de la serie. Lo más complicado va a ser obtener ese código. Como ejemplo práctico se van a leer los últimos cuatro datos publicados en la encuesta EPA del número de ocupados en España.
Para saber el código correspondiente a la serie con el número de ocupados hay que ir al Generador de URLs JSON del INE y seleccionar:
- Operación estadística: Encuesta de Población Activa
- Tipo de información: Series (solo definición, sin datos)
- Seleccionar una función: Obtener las series que forman una tabla
- Refina tu consulta: Expandir «Encuesta de Población Activa -> EPA. Base poblacional 2011 -> Resultados Trimestrales -> Resultados nacionales -> Ocupados» para poder seleccionar «1.1.2.1.3.1 Ocupados por sexo y grupo de edad. Valores absolutos y porcentajes respecto del total de cada sexo»
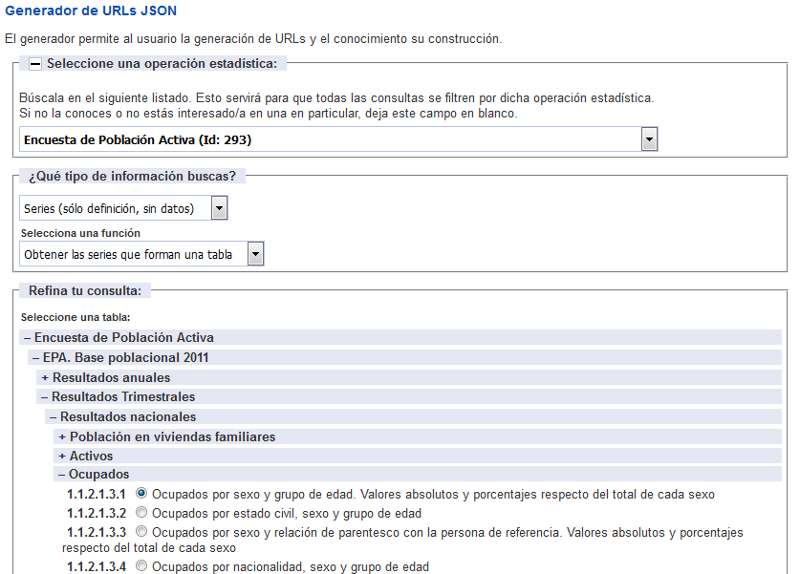
Pulsar entonces el botón «Generar peticion» y pinchar la URL generada, que es http://servicios.ine.es/wstempus/js/ES/SERIES_TABLAOPERACION/4076/293?page=1. Se ve entonces una página con la lista de series así como su código correspondiente. Aunque el formato mostrado es en JSON, es muy legible. Por ejemplo, en este caso el inicio del texto es:
{"Id" : 87, "COD" : "EPA87", "FK_Division" : 166, "FK_Operacion" : 293, "Nombre" : "Total Nacional. Ambos sexos. De 16 y más años. Ocupados. Personas. ", "Decimales" : 1, "FK_Periodicidad" : 3, "FK_Publicacion" : 330, "FK_Clasificacion" : 19, "FK_Escala" : 4, "FK_Unidad" : 3},
{"Id" : 273709, "COD" : "EPA273709", "FK_Division" : 166, "FK_Operacion" : 293, "Nombre" : "Ocupados. Total Nacional. Ambos sexos. De 16 y más años. Porcentaje respecto al sexo. ", "Decimales" : 2, "FK_Periodicidad" : 3, "FK_Publicacion" : 330, "FK_Clasificacion" : 19, "FK_Escala" : 1, "FK_Unidad" : 101},
[...]
Por simple inspección se ve que la serie cuyo «Nombre» es «Total Nacional. Ambos sexos. De 16 y más años. Ocupados. Personas.» le corresponde el «COD» (código) de «EPA87». Este es precisamente el código que se estaba buscando.
Estas series corresponden a una tabla del INE. En este caso, a la tabla de Ocupados por sexo y grupo de edad. Valores absolutos y porcentajes respecto del total de cada sexo de las tablas de la EPA. En la página de la tabla se ve que las unidades usadas en la serie son miles de personas.
Ahora ya se tiene todo lo necesario para escribir el código. Primero, se define la plantilla de URL del INE y sus valores, para calcular la URL con los datos:
url_plantilla = 'http://servicios.ine.es/wstempus/js/ES/DATOS_SERIE/{codigo}?nult={num_datos}'
codigo = "EPA87"
num_datos = 4
url = url_plantilla.format(codigo=codigo,
num_datos=num_datos)
Nota: Las líneas largas del código aparecen como en varias líneas, pero si se hace un copia&pega, se obtiene el código correcto.
Para leer los datos de la web del INE se usará la librería biblioteca Requests, por su facilidad de uso.
import requests respuesta = requests.get(url)
Y se puede mostrar por pantalla lo que se ha leído:
print(respuesta.text)
Que es:
{"COD" : "EPA87", "Nombre" : "Total Nacional. Ambos sexos. De 16 y más años. Ocupados. Personas. ", "FK_Unidad" : 3, "FK_Escala" : 4, "Data" : [{"Fecha" : 1443650400000, "FK_TipoDato" : 1, "FK_Periodo" : 22, "Anyo" : 2015, "Valor" : 18094.2, "Secreto" : false, "Notas" : []},
{"Fecha" : 1435701600000, "FK_TipoDato" : 1, "FK_Periodo" : 21, "Anyo" : 2015, "Valor" : 18048.7, "Secreto" : false, "Notas" : []},
{"Fecha" : 1427839200000, "FK_TipoDato" : 1, "FK_Periodo" : 20, "Anyo" : 2015, "Valor" : 17866.5, "Secreto" : false, "Notas" : []},
{"Fecha" : 1420066800000, "FK_TipoDato" : 1, "FK_Periodo" : 19, "Anyo" : 2015, "Valor" : 17454.8, "Secreto" : false, "Notas" : []}]}
Se ve que los datos están en el campo Valor, y las fechas en el campo Fecha, pero hay que tener en cuenta que la fecha está representada como milisegundos en tiempo UNIX. Pero con unas líneas más de código se pueden mostrar los datos en pantalla de forma legible:
import datetime
print(datos['Nombre'])
for x in datos['Data']:
fecha = datetime.date.fromtimestamp(
x['Fecha'] // 1000)
ocupados = x['Valor']
print(fecha, ocupados)
Que mostraría:
Total Nacional. Ambos sexos. De 16 y más años. Ocupados. Personas. 2015-10-01 18094.2 2015-07-01 18048.7 2015-04-01 17866.5 2015-01-01 17454.8
La conversión de fecha ha funcionado correctamente porque se ha ejecutado el programa en el mismo huso horario que en el que fueron generados (Madrid).
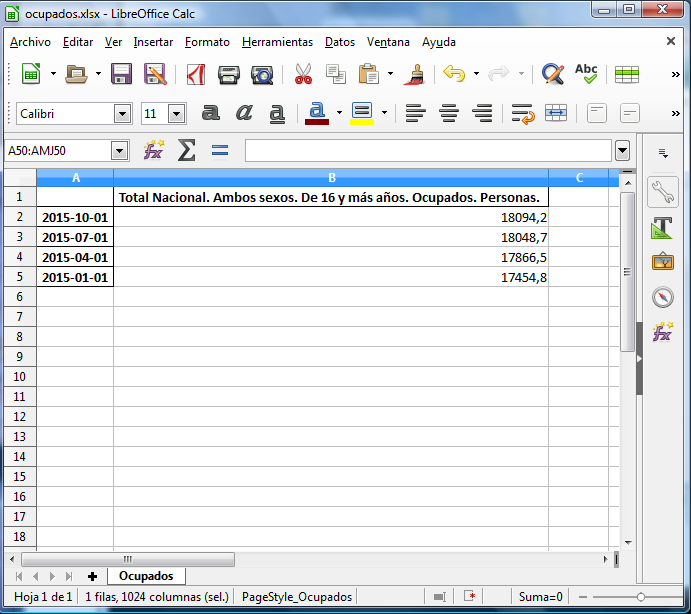
Con la biblioteca pandas se pueden guardar estos datos fácilmente en un fichero excel, y además hacer la conversión adecuada de fechas:
import pandas as pd
nombre = datos['Nombre']
fecha_serie_utc = pd.to_datetime([x['Fecha'] for x in datos['Data']], unit='ms', utc=True)
fecha_serie_madrid = fecha_serie_utc.tz_convert('Europe/Madrid')
fecha_serie = [x.tz_localize(None).date()
for x in fecha_serie_madrid]
ocupados_serie = [x['Valor']
for x in datos['Data']]
tabla = pd.DataFrame(ocupados_serie,
index=fecha_serie,
columns=[nombre])
with pd.ExcelWriter('ocupados.xlsx') as documento_excel:
tabla.to_excel(documento_excel, 'Ocupados')
Con este código se generaría el fichero ocupados.xlsx con los datos mostrados anteriormente:
Finalmente, por conveniencia para copiarlo, se incluye el código completo desde la lectura de los datos del INE hasta la creación del fichero excel:
import requests
import pandas as pd
url_plantilla = 'http://servicios.ine.es/wstempus/js/ES/DATOS_SERIE/{codigo}?nult={num_datos}'
codigo = "EPA87"
num_datos = 4
url = url_plantilla.format(codigo=codigo,
num_datos=num_datos)
respuesta = requests.get(url)
datos = respuesta.json()
nombre = datos['Nombre']
fecha_serie_utc = pd.to_datetime([x['Fecha'] for x in datos['Data']], unit='ms', utc=True)
fecha_serie_madrid = fecha_serie_utc.tz_convert('Europe/Madrid')
fecha_serie = [x.tz_localize(None).date()
for x in fecha_serie_madrid]
ocupados_serie = [x['Valor']
for x in datos['Data']]
tabla = pd.DataFrame(ocupados_serie,
index=fecha_serie,
columns=[nombre])
with pd.ExcelWriter('ocupados.xlsx') as documento_excel:
tabla.to_excel(documento_excel, 'Ocupados')
ACTUALIZACIÓN (15 de abril de 2018)
Cuando se lee el json (respuesta.json()) ya no hay que ponerle el [0] (respuesta.json()[0]
1 opinión en “Tutorial para leer con JSON las estadísticas del INE”
Comentarios cerrados.